

What's different? Part one: Sequencing
What's different? Part one: Sequencing
DNA Sequencing is eating the world

Overview
Technology is dramatically changing our relationship with biology. After a productive century with many foundational discoveries, our capabilities are beginning to compound in ways that they haven’t before. This is especially true for genetics. Just a matter of decades ago, a PhD in genetics often consisted of sequencing a gene. Now, graduate students sequence genomes, and carry out massive functional studies perturbing every gene that is expressed.
What’s different?
One simple model that has gained traction is: read, write, edit. This model leans heavily into the analogy of DNA as the source code of an organism. We have made enormous strides in DNA sequencing—letting us read the source code. Modern DNA synthesis technology lets us write new code. You can likely guess where DNA editing technologies like CRISPR fit in the model.
While this model is useful, I prefer to focus on the broadly enabling technologies themselves, a level of abstraction one layer below their purposes. When I think about what is different in the world of genetic technologies, I think about Sequencing, Synthesis, Scale, and Software. I find that this mental model helps frame a wide range of current research. It also helps explain the emergence of a new phenotype of biotech startup.
Over the course of a four part series, I am going to provide an overview of each of these components. Each post will build on the previous one, with the goal of showing that this is a new integrated stack of technologies. Incredible things are now possible at the intersection of these areas. The story begins with sequencing.
Sequencing
One figure has permeated throughout the majority of introductory slides for genomics lectures and courses:

This widely used figure provides historical context for the insanity of modern DNA sequencing. It shows that the decline in sequencing costs has dramatically outstripped even Moore’s Law—which describes the cost decline in electronics that has enabled us to walk around with more computation in our pockets than it took to land a man on the moon.
Despite a bit of recent price stagnation around $1000, the sequencing market is heating back up. Historically, the most dominant force in this space has been Illumina. Illumina provides a technology called massively parallel sequencing—more commonly referred to as next-generation sequencing (NGS). Ironically, NGS is not that conceptually different than Sanger sequencing, which was the first generation of sequencing technology.
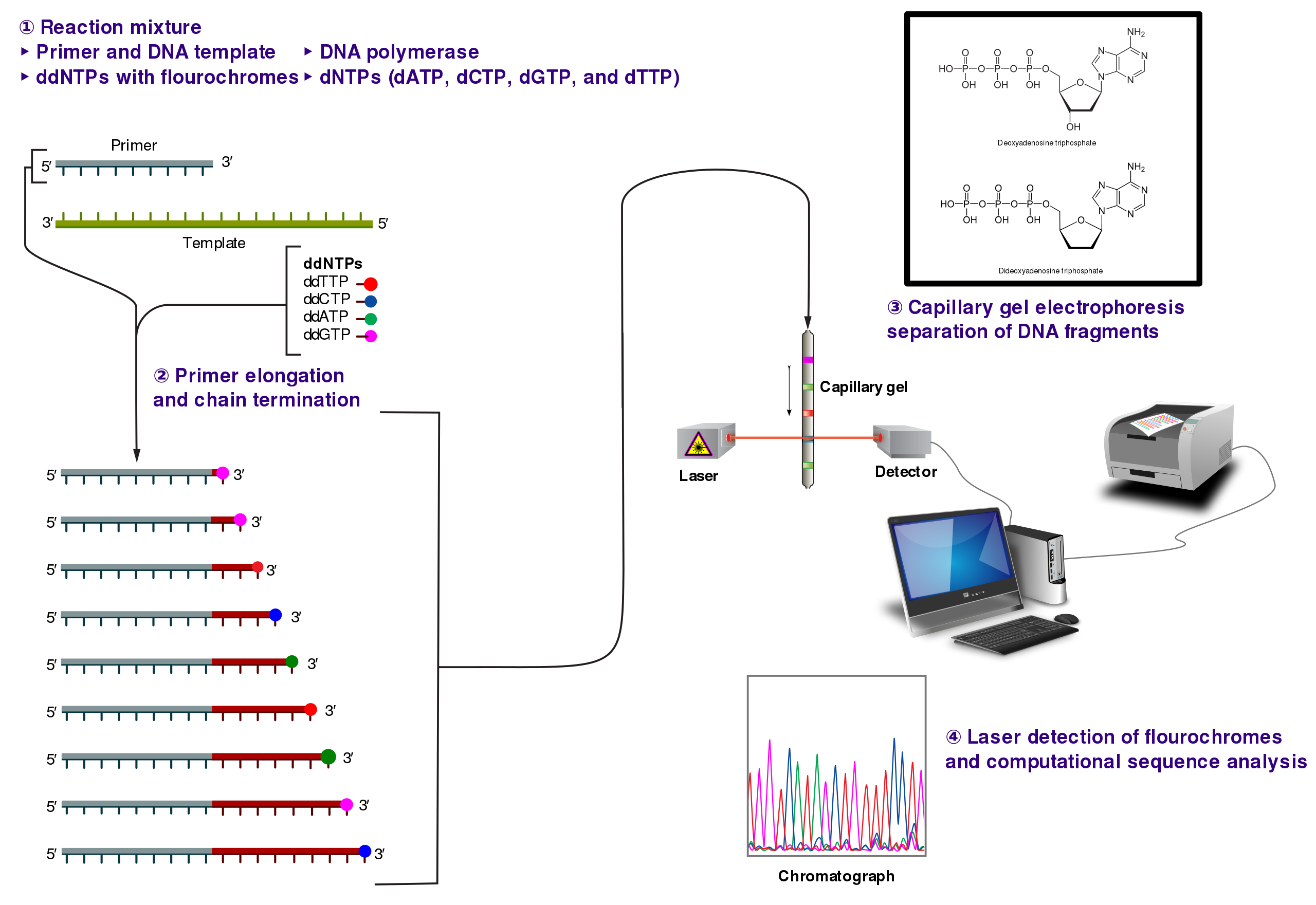
{kind=link}
The idea behind Sanger sequencing is actually quite elegant. At each step, special fluorescently labelled bases of DNA are added. They are designed to terminate the extension reaction once incorporated. The color read out indicates which base was present in the sequence. Even according to Illumina, “The critical difference between Sanger sequencing and NGS is sequencing volume. While the Sanger method only sequences a single DNA fragment at a time, NGS is massively parallel, sequencing millions of fragments simultaneously per run.”
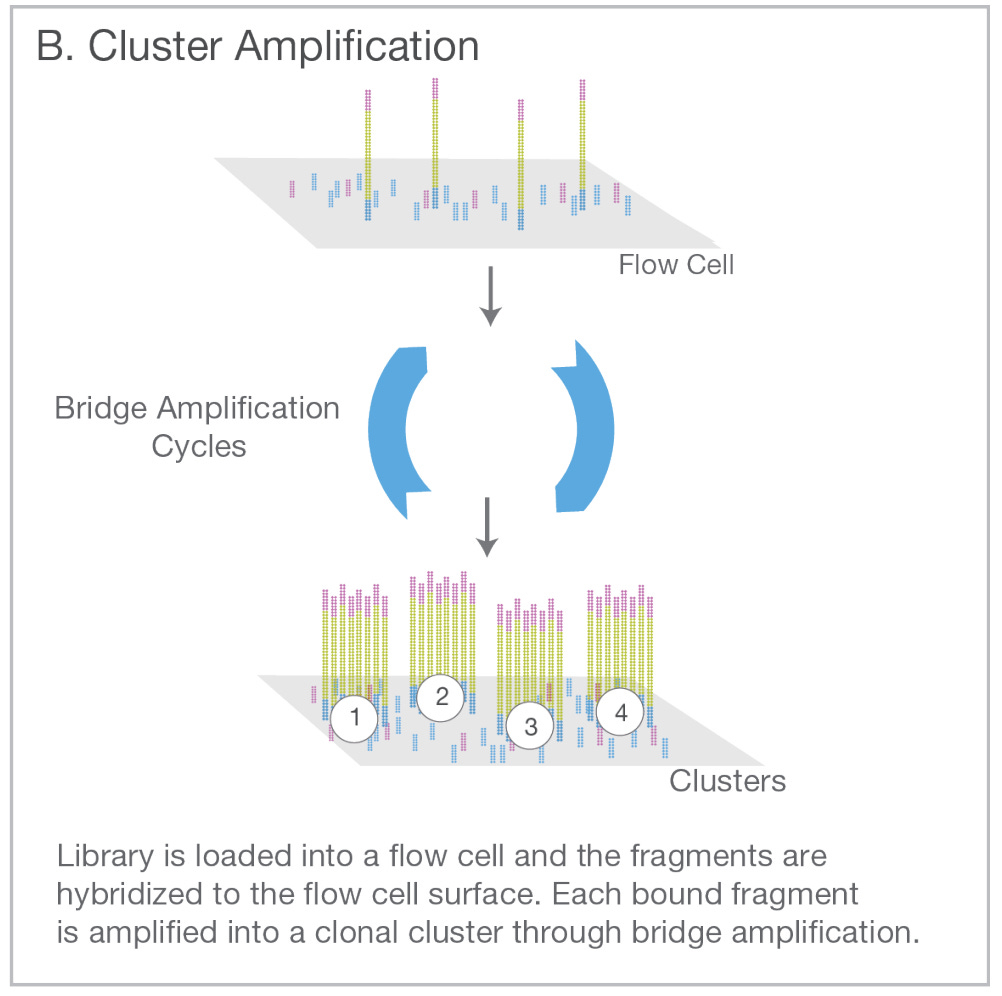
Illumina has been able to parallelize this basic type of sequencing reaction by developing sophisticated flow cells (seen above) using semiconductor manufacturing technology. Clusters of DNA sequences that are spread across the flow cell can be simultaneously sequenced. This type of scale is what makes genomics possible. We can now make measurements accounting for all of the bases in the human genome.
New technologies are challenging Illumina’s market dominance. Companies such as Oxford Nanopore and Pacific Biosciences are competing by developing fundamentally new approaches to DNA sequencing. Both companies are developing long-read sequencing technologies which make it possible to analyze complex sequences of the genome that were difficult or impossible to measure with technologies like Illumina. These technologies are moving us closer to a future where an individual’s genome could be sequenced and assembled in an automated fashion.
Two other exciting new companies are Singular Genomics and Element Biosciences. They have both released impressive new sequencing instruments aimed to directly compete with Illumina, which should drive down NGS costs. Another inflection point will likely be when Illumina’s patent protection expires. This could enable competitors like the Chinese company BGI to be more competitive in the U.S. market. All of this innovation could set us back on the path towards a $100 genome in the near future.
The DNA sequencing revolution will change all of our lives over the next century.
Just last year, a project called the UK Biobank generated whole-genome sequencing (WGS) data for 200,000 individuals—the largest amount of sequencing data in history. The project aims to release data for 300,000 more individuals in 2023. In the United States, the All of Us program aims to generate WGS for over a million Americans. This would have been unimaginable only a decade ago.
As the scale of sequencing increases, genetics will expand in impact. This type of data will begin to describe the complex relationship between genetic variation and health outcomes. It will have uncontroversial benefits like finding better drug targets for diseases, and greatly improving precision medicine—where patients are matched with drugs based on their genetics and other personalized data.
Sequencing will also be used more directly in clinical care. A lab at Stanford recently broke the world record for the fastest clinical diagnosis based on genetics—going from sample to causal mutation in just five hours. Liquid biopsies are another great example of clinical sequencing, where DNA in the blood is analyzed to detect cancer at its earliest stages. Companies such as Grail are working to make this a reality.1
As the cost of sequencing continues to decline, it will likely become a ubiquitous tool for monitoring our bodies and health. Beyond our genomes and the DNA in our blood, a large amount of evidence shows that it is important to sequence and understand the microbes that live on and inside our bodies. It has been shown that the composition of an individual’s gut microbes can be highly predictive of disease outcomes, and can even predict spikes in blood sugar after eating different types of food. This type of measurement could become essential for understanding how different diets actually impact our bodies on an individual basis.
There will also be more complex and far-reaching applications. Just a few weeks ago, a study was published in Nature Medicine describing an approach to infer the genome sequences of IVF embryos to assess disease risk. A week later, another study was published in Nature Genetics that used genetic models to predict the highest level of education that people would complete. Both studies represent applications of genetic technologies to some of the most intimate and fuzzy parts of human life—from birth to important social outcomes.
These types of studies immediately initiate fierce debates. They trigger the imagery that Gattaca and other dystopian Hollywood movies have embedded in our minds. They also evoke fears of repeating some of the darkest moments of the 20th century that were based on ideas of eugenics. We live in a world where less than a century ago the U.S. Supreme Court ruled in favor of compulsory sterilizations.
As, the Russian novelist Aleksandr Solzhenitsyn wrote, “The battle line between good and evil runs through the heart of every man.” With this deep historical scar tissue, we need to bring technical rigor and humility to the application of genetic technologies. This will be crucial as methods continue to improve and the sampling density of the population increases.2 We need to collectively work towards a future where this technology is used to increase human agency and flourishing.
Next time: Synthesis
I’ve aimed to provide a broad overview of why DNA sequencing is eating the world. We are living through one of the most incredible cost declines in technological history. Sequencing alone is enabling totally new types of studies, technologies, and companies. This will help us be less reactionary and more predictive about our health.
The next post in this series will cover DNA synthesis. While it hasn’t experienced the same rate of improvement as sequencing, commoditized synthesis is a foundational pillar for modern genomics and biotech. I’ll explore recent advances in this space that may lead to an even bigger paradigm shift than sequencing did.
Some of the most exciting innovation happens at the intersections between different technologies. As this series continues, I will show how Sequencing, Synthesis, Scale, and Software are being combined in creative ways to unlock fundamentally different approaches to biological science and engineering.
This could revolutionize cancer care. Early stages of cancer are far more responsive to treatment. I’ve written about some of the primary literature in this space already. It’s a topic that I plan to write more about in the future.
Sample size is incredibly important in genetics. An example of this is a recent preprint that analyzed genetic variants associated with height in over 5 million individuals—the largest genome-wide association study to date. The authors claimed to account for nearly all of the heritability of height for Europeans. As sample sizes increase, studies like these start to asymptotically approach these types of results. Polygenic risk scores will also improve, because they are primarily based on GWAS summary statistics.
Look forward to the rest of this series Elliot! Especially curious to hear your thoughts on DNA synthesis, and how enzymatic approaches might evolve over time.
I might also add that beyond breakthrough technologies enabling us to understand how our genomes impact health, our ability to make meaning out of this new information is critically important. I shared some brief thoughts on this today: https://healthandwealth.substack.com/p/genetic-counseling
Great post! Given the general interest focus of this series, I hope you won't mind some noob clarification questions (coming from someone whose last exposure to Biology was AP Bio in the early 00's) about the
"[Sequencing data] will have uncontroversial benefits like finding better drug targets for diseases"
- Can you provide an example?
- If we've already sequenced a bunch of people, can you give some intuition around how and why sequencing many more will lead to finding better drugs for certain diseases?
"[Sequencing data] will greatly improve precision medicine-where patients are matched with drugs based on their genetics"
- Can you give an example?
- How can we learn this relationship? Even when the health outcomes are easy to measure (not the case in mental health, for instance) how exactly would we be able to detect that certain drugs are more effective for people certain genes? From a statistical standpoint, if there are dozens of genetic subpopulations that may respond differently to dozens drugs for a given disease, doesn't that lead to an explosion of treatment groups during clinical trials?
"Sequencing will also be used more directly in clinical care," and the two examples you give are diagnostic.
- Can you explain the first example? (What's a causal mutation?)
- In the simplest case, I understand how cheap sequencing could detect things like congenital single gene diseases. And though I don't understand what polygenic risk scores measure, exactly, I understand being able to say "people with a genetic makeup similar to yours go on to develop [insert disease here] x% of the time." And how that would lead you to take preventive steps to addresses [insert disease]. So, given that we already do seem to do this when people's lifestyle or demographics are similarly predictive of [insert disease], how much extra predictive power does sequencing give us?
- Going beyond "you were born with these genes, and we know that causes or is at least a risk factor for [insert disease]," the cancer diagnosis example seems to imply "we can detect disease before it fully develops because it's changed your DNA." Are there any other diseases that we can detect in this "non-congenital" way?
"[Sequencing gut microbes] could become essential for understanding how different diets actually impact our bodies on an individual basis." The dismal state of nutrition science suggests that we already have a hard time measuring the relationship between diet and impact on our bodies (likely because there are so many input variables, and the interesting outcomes take years if not decades to manifest). Would adding the additional variable of gut micro composition somehow make this topic easier to study, instead of harder?
Thank you!